Beyond build vs buy: AI infrastructure that actually scales
The "build vs. buy" debate is one of the most persistent in enterprise AI. But framing AI infrastructure as a binary decision misses the point.

António Calçada

The "build vs. buy" debate is one of the most persistent in enterprise AI. But framing AI infrastructure as a binary decision misses the point.
AI Infrastructure isn't static, it must evolve across new standards, compliance demands, distributed teams, and business units. Scalability and sovereignty, the real criteria for long-term success, depend on flexibility and observability by design, not just initial speed.
Buying often moves complexity downstream. Building creates challenges for teams who can’t or won’t own it long term. The result? Delayed rollouts. Fragile architectures. Short-lived wins.
And this isn’t a niche problem. 78% of global organisations now run AI in at least one function, but 74% say they fail to scale it effectively. The pilots work, but the platforms don’t hold.
So let’s take a closer look at where things break and how teams are starting to make it work.
Why buying AI infrastructure breaks down after year one
Most organizations buy AI platforms under pressure: frozen headcount, executive expectations, and the need to “show something” fast. Vendors appear with slick demos and promises of smooth onboarding.
Initially, it works. Quick wins. Clean UI. A few production deployments.
But then reality sets in:
Workflows don’t map cleanly to existing processes
Integration gets messy and opaque
Observability is an afterthought
Governance is bolted on late—if at all
Audit and compliance issues emerge
In fact, that last point is about to get a lot more real. With the EU AI Act now in force, and systemic-risk compliance rules hitting by August 2025, AI systems that can’t show audit trails, rollback support, and runtime visibility will be out of bounds.
Most vendor platforms do what they’re designed to do. The issue is what happens when that design doesn’t match your environment, your security processes, or your growth curve. Buying can solve the pilot. It rarely solves the platform. Especially when the system underneath it wasn’t built to change.
In short, buying doesn't remove complexity, it moves it downstream.
Why building AI infrastructure sounds great, until you own it
On the surface, internal builds seem like the safer long-term play: full control, tailored workflows, complete ownership. No vendor lock-in. No waiting for roadmap updates.
But control comes with cost, often underestimated.
Even large enterprises struggle to staff the teams needed to maintain internal infrastructure. And the engineers you do hire aren’t signing up to maintain orchestration frameworks or debug monitoring pipelines. Over time, observability gets deprioritised. Governance slips. Ownership blurs.
Eventually:
New teams inherit half-documented systems.
Glue code fills the gaps.
Versioning disappears.
What was built to fit perfectly starts to creak under scale.
And then there’s the pace of change with new frameworks, new LLMs, new business requirements, non-optional updates that demand time from teams already stretched thin. So as well as building the AI infrastructure, you will also need to maintain it indefinitely.
Infrastructure isn’t a one-time build. It’s an ongoing engineering commitment.
What’s working instead: Hybrid AI infrastructure
Between brittle vendor platforms and high-maintenance internal stacks, a new pattern is emerging: hybrid AI infrastructure.
The architecture is simple but powerful:
Standardize what should be repeatable
Customize where it matters
Connect everything through open-by-default interfaces
This often means deploying an orchestration and observability layer, leveraging any model including your own models and pipelines, using SDKs and APIs to integrate with internal systems and enforcing governance at the infrastructure level.
Of course, the value isn’t just in flexibility, but in the clarity and scalability this provides. Boundaries are explicit, interfaces are documented, and teams don’t have to reverse-engineer someone else’s logic just to ship a new use case.
It’s already working in large-scale and complex environments where teams are distributed, compliance isn’t optional, and AI needs to flex across business units.
Here are just a handful of real case examples:
Insurance claims automation
A multinational insurance broker deployed Noxus to automate 75% of FNOL claims with 93% precision, cutting processing time dramatically and positioning themselves as an industry innovator. Human-in-the-loop escalation, fine-grained control, and data lineage tracking made it scalable and auditable from day one.
Call centre agent onboarding
A global BPO provider used Noxus to unify fragmented onboarding knowledge into a central, AI chat interface. This reduced onboarding time for new clients to under a month, improved agent accuracy to 93%, and ensured compliance observability across every response.
Retail catalogue management
HOL Holding’s retail brands, including 360hyper and Saibarato, automated over 15,000 daily product listings using Noxus. This enabled for real-time catalogue management, instead of monthly updates, with a 94% precision - all delivered in just 80 days.
Bottom line: This is a proven structure for moving faster without stacking technical debt behind the scenes.
What hybrid-ready infrastructure looks like in practice
For all the talk of hybrid models, most teams still end up navigating edge cases without a clear blueprint. The good news: patterns are starting to emerge. Enterprises making it work tend to align around a few shared principles:
1. Flexible infrastructure
Deployment must support different models, runtimes, and data sources. Noxus uses horizontally scalable orchestration, model failover, and adaptive routing to enable this.
2. Real observability
More than dashboards: full data lineage, version tags, permission-aware logs, and token-level metrics across LLMs.
3. Built-in governance
Every deployment has embedded auditability, rollback support, and access controls, not as add-ons, but as foundational infrastructure. The EU AI Act now mandates exactly this for high-risk systems, and non-compliance could mean fines up to €35 million or 7% of global revenue.
4. Composable Tooling
Tools that don’t assume they’re central. Noxus SDKs allow you to extend, override, and plug into any layer, without breaking upstream or downstream logic
5. Clear team responsibilities
When orchestration, logic, and deployment layers are modular, ownership becomes transparent, and sustainable through team changes.
These principles are what differentiate scalable AI systems from brittle ones.
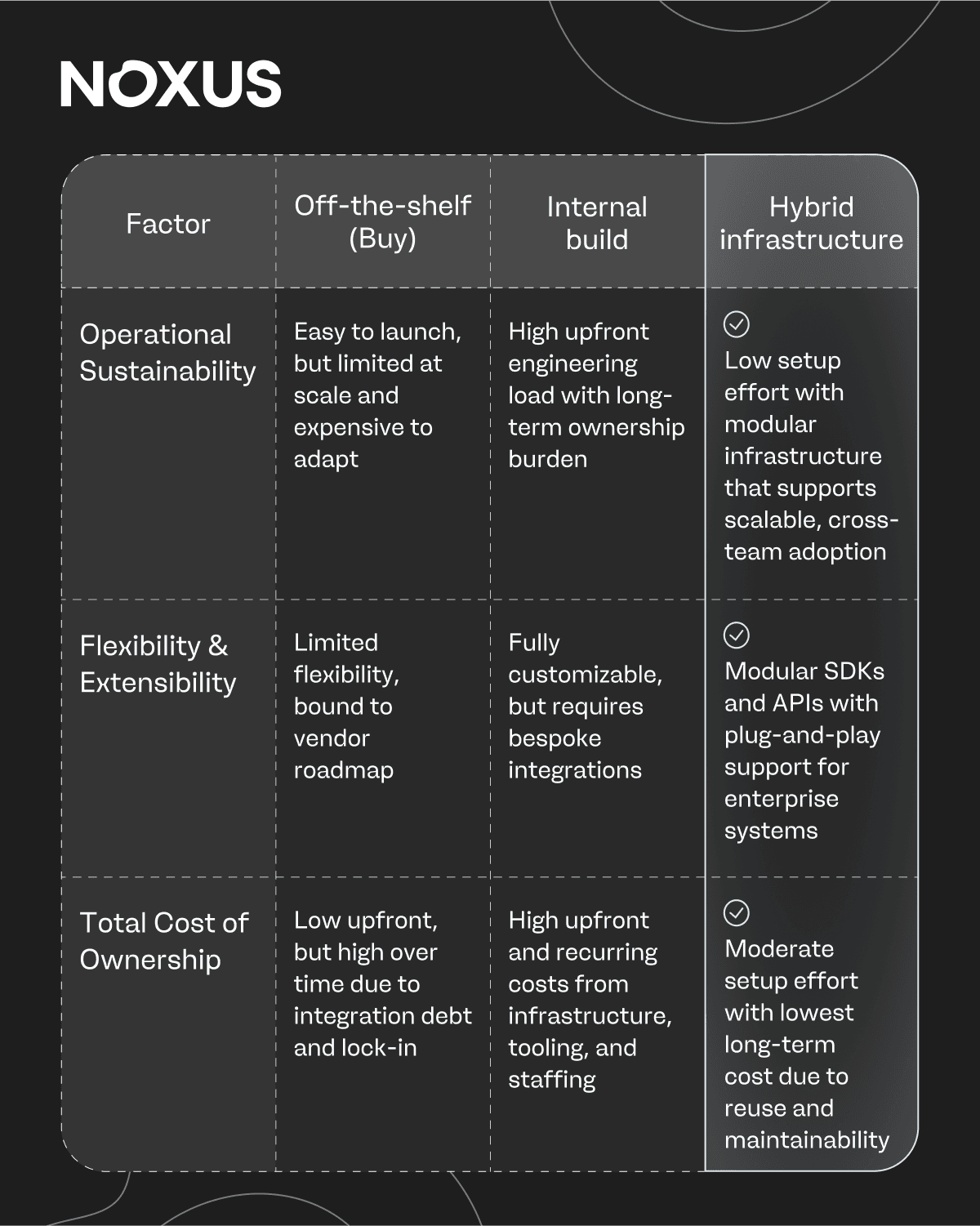
Scaling AI starts with structure
Most AI infrastructures don't fail at launch, they fails at scale.
The pressure to show results fast leads to shortcuts like quick pilots, duct-taped integrations, governance added later (if at all). By year two, the cracks show. Teams start again, just with more constraints than before.
Off-the-shelf tools feel easy at first, but become rigid as complexity increases. Internal builds feel strategic, but turn into cost centers unless resourced like a product. Both approaches struggle to support widespread adoption across teams and use cases.
Hybrid infrastructure offers a third path:
It combines low setup effort with a composable architecture that scales with adoption, without needing to rebuild for every new use case.
Let’s break that down:
Enterprises that scale AI effectively aren’t choosing between build and buy, they’re designing for sovereignty, governance, and adaptability from day one.
If your architecture already feels fragile or if your team’s stuck relitigating infrastructure every six months it might be time to reframe the question. Not whether to build or buy. But how to set things up so the next decision is easier, not harder.










